Cloud-Native Geo Data Explorations with Google Open Buildings
I’m pretty sure it’s been at least a couple years since I’ve written any blog post that’s not some sort of release or ecosystem update on STAC or GeoParquet, and I’d like to try to get back into writing more. But I’m going for a modest start — I mostly just want to share some of my explorations with cloud-native geospatial data.
Most of my energy on open stuff for the last year has been on GeoParquet, as it feels like it has a ton of potential (which is a whole other half started blog post I aspire to finish) and it’s been fun to be back in vector data land. The spec is in pretty solid shape, and we plan to release 1.0 soon. One of the things I wanted to see for 1.0 was more data in GeoParquet, and particularly really large datasets. So after two failed attempts to use ChatGPT to get me coding again, I decided to try it out to help me transform Google’s Open Buildings dataset into GeoParquet.
Tom Augspurger’s work on Microsoft’s Building Footprints distribution in Planetary Computer was my inspiration — I mostly wanted to see if I could roughly replicate what he’d done, as the default distribution of the Google Dataset just made me shudder. And it turns out the GPT-4 on geospatial data munging tasks works really damn well. The whole experience with ChatGPT is worth a whole other post, that I’ll try to write, but the quick summary is that it’s got me back into coding after 15 years away, enabling me to actually iterate on the problem instead of mostly being flummoxed by syntax and build environments.

The other awesome thing to emerge recently is source.coop (read their FAQ for more info), which is providing free hosting for openly licensed cloud-native datasets, so I had a clear place to put a cloud-native version of Google’s Open Buildings. So I dug in, learning a bunch of new tech to get it done. It ended up taking me a lot longer than I expected, mostly due the size of the dataset — both some of the individual files (over 10 gigs) and the total size of the dataset (150 gigs+). It turns out that even with a pretty beefy laptop you start to get memory issues, and also most of the complete processings of the dataset take 10+ hours. Plus this was a nights and weekends project, and I’ve now got a 4 year old, which means a lot less free nights and weekends.
In this post I’m going to mostly describe the overall path to getting to the partitioned GeoParquet dataset on source.coop. But I also hope to use it as the start of a series of posts going deeper into each step, and try to push out code and/or performance comparisons for each step. The main thing driving me revisiting the work is that a couple weeks after I finished fully processing the partitioned Open Buildings dataset Google went and released ‘v3’, which includes an additional buildings from India and South America. So I’ve been redoing all the steps I got to in with v2, but writing code so others can experiment, and comparing the approaches. So expect more blog posts in the coming weeks as I work through the steps and make more reusable open source code.
The Google Open Buildings Dataset
So first, the good — this data is awesome. Google probably has the single best collection of imagery of the earth, and also some of the best AI / computer vision people. AI / ML clearly extensively used in Google maps, and it’s amazing that they took their data and ML and openly released the data under about the best possible license for foundational data — dual CC-BY 4.0 & ODbL. It’s a dataset that’s useful for many purposes, and it’s so cool that they keep expanding it. And it’s distributed without any login, it’s got a nice little viewer to help download the data, and the command to download all the data is clearly documented and pretty easy to use.
But… the distribution leaves a lot to be desired. It’s a series of gzipped CSV files, divided into S2 grids. The S2 grid isn’t meaningful to anyone — if you want a particular country you need to look on the map and download up to 4 different files. These files are of drastically different sizes — from one that is 1 kilobyte of 3 buildings in the middle of the Indian Ocean to ~14 gigabytes (5.9 gzipped) with 60 million buildings in Indonesia in V2 and ~20 gigabytes (8.3 gzipped) with ~88 million in India in V3.

The CSV files can’t be opened seamlessly with any GIS — there is not GeoCSV format, so your tool will either make some guesses or need some manual intervention. The CSV has both latitude & longitude columns and Well Known Text in a geometry column, which gives it flexibility but also is redundant information for any GIS, since calculating the centroid of a building is quite easy. And then the third problem was that some small percentage of the geometries were multipolygons, not polygons. I’ll try to get the stats, but definitely under 1%, and probably under 0.1%. This isn’t a huge deal, and indeed some formats like Shapefile don’t differentiate between the two. But for many formats if you’re trying to script things it’ll assume all polygons and then barf when it hits a polygon. It’s easy to fix, but fairly annoying.
So my goal was to get to a distribution of the data that fixed those three main problems, and then to experiment with Parquet partitioning, since it seemed potentially promising for geospatial data. I also wanted to get STAC metadata for it, which I didn’t quite get for v2, but will for v3. I’ll do detailed posts on the various steps, since this is already getting long, but I’ll sketch out the main flow of things.
Multipolygon Cleanup & Format Transformation
First step was to download all the CSV’s, unzip them and get them into GeoParquet and/or FlatGeobuf, splitting any multipolygons into their polygon parts (recalculating the area and the plus code and just leaving the confidence the same for each). For v2 this was all GeoPandas, and it was mostly great to work with, but when I was getting to 10 gig files it was taking up more than all my memory, using lots of swap and generally struggling. So to make it work I’d close all my programs and run overnight. I’d heard great things about GeoPandas for years, and it was awesome to dig in and find out for myself how nice it is to work with. And it’s where GeoParquet started, with Joris Van den Bossche work adding to_parquet and read_parquet. Those functions were awesome, and later benchmarking confirmed how quick they were. It was also just cool to see how the output files were so much smaller as well.
PMTiles for Visualization
FlatGeobuf was also great to work with, and a key part of the workflow, as it’s what I used to generate PMTiles with Tippecanoe. Tippecanoe deserves its own love letter blog post; it’s just a stellar tool and I believe it is foundational for a cloud-native vector future. My files were big enough that Tippecanoe would barf on some of them, I think maybe over 10 gigabytes or so? But once I just broke them up in to 2–3 gig parts things worked great. The resulting ~100 gig PMTiles files really show the power of the cloud-native geo approach, check it out on observable. I hope to help get it supported in more tools and make better viewers for it (and my dream is that Felt will just let you point directly at a PMTiles).

If you’re not using PMTiles then I highly recommend checking it out. Felt is the foremost user of it, enabling any user to ‘upload anything’, up to 5 gigabytes of data. There were a number of ‘cloud native MBTiles’ formats, but I think v3 of PMTiles took the best of all that had been done and put it all in one amazing package.
Better Partitioning
Then the biggest challenge was to do something better than S2 grids to break up the data. I independently came to the same conclusion that Darell van der Voort laid out in his blog post — that administrative boundaries provide a potentially naturally balanced partition for buildings than a regular grid, since states and counties get smaller when there’s lots of density, and much bigger when there’s a really sparse population.
I went with just level 1 admin boundaries (states or provinces), instead of level 2 like he did, since my target was Parquet and it does a good job internally with row groups, while BigQuery seems to do better with smaller partitions. I also really wanted to see if the individual partitions could be useful as independent files — could a global geospatial dataset not only serve a big Spark process but also be a directory structure that a desktop GIS person could navigate to download just the country or state that they wanted?
Having tons of little counties seemed excessive, and most all files were under 2 gigabytes, which seemed reasonable for ‘scale out’ scenarios where you’d have a VM working in parallel on each data chunk. But I’m far from an expert on that, so anyone’s advice is welcome, and I think there’s lots more experiments to be done. This is where I did diverge from the Microsoft Buildings Dataset distribution on Planetary Computer, as it just partitions by a regular grid.
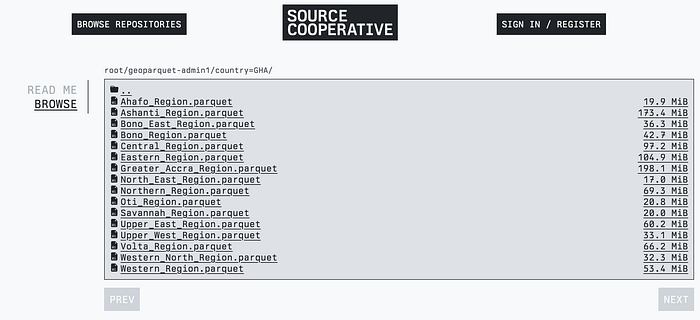
But I did like that the resulting partitioned structure was decently ‘legible’ — I named the files by the state, in the right country directory, so you can easily browse on source.coop and just hit ‘download’ on the state files they wanted, and also can easily stream a whole country with OGR or DuckDB. You can check out the tutorial I made on how to do this with DuckDB.
Creating the admin level 1 attributes
The center of this challenge was a large spatial join, to add country and admin 1 attributes to every building footprint. I found the GeoBoundaries CAGZ dataset which is pretty awesome. GADM looks sweet, and a bit better on coastlines and it seems to have more islands, but that non-commercial term is just killer for me. Maybe my use is ok? Just to join in a dataset, not to make a map? But the point is I’m not a lawyer and I have no idea, so much better to go to one without non-commercial terms (though a real Creative Commons license would be even better. I hope to find some way to contribute to it (I do wish someone would solve the ‘github for geospatial’ so we could all collaborate on individual datasets instead of having OSM be the only option, but that’s a whole other blog post).
After a number of struggles I ended up loading the whole thing into PostGIS, which did the job, but was more of a pain than I was expecting. I first just put attributes on every building that was within a admin level 1 polygon, but it missed tens of millions. Investigation revealed that many of the missing ones were in Angola, due to a quirk of GeoBoundaries (using a different field to have the country). But then it was also a bunch of buildings on the coastline and in islands that didn’t match the boundaries. I ended up just having it use the nearest admin 1 boundary for all those that weren’t within one. I think I did end up using the actual polygon, not just the centroid, for the calculation of ‘nearest’, but I’m sure there’s still places where it’s wrong. But it seemed better to at least get every building into a boundary than to have some that were just blank.
I also made some boneheaded mistakes, like writing out the individual admin 1 files with a WHERE based just on the admin 1 name, not the admin 1 name and country. Turns out that there’s at least 20 instances of provinces / states that have the same name, like ‘Eastern Province’. So each of those had double (or more) the number of buildings, since each contained all the buildings in any Eastern Province.
Then the final step was experimenting spatial joins, which was where I discovered DuckDB. Which holy s___ is probably my favorite new technology of the last 5 years. Or at least it will be if they live up to their promise with geospatial support, which was only recently added but which is already useful. That’s worth a whole post as well, but it was a lot of fun to discover and play with, and I think it’s actually one of the nicer ways to work with the resulting partitioned GeoParquet files.
Results and Next Steps
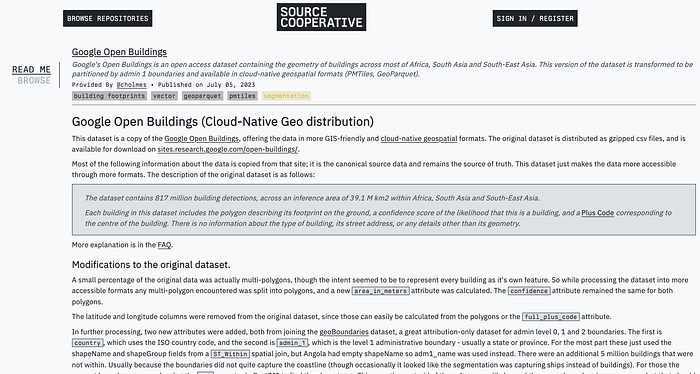
So you can see all the resulting dataset distributions at beta.source.coop/cholmes/google-open-buildings — I hope they’re useful! After I got the data up I had a list of next steps, including making a better PMTiles viewer, since it’s really nice to be able to see the whole dataset with ease, trying out Delta Lake and/or Iceberg (as Tom got some really nice results with Delta) and also get STAC metadata on the data— at least at the collection level.
But then v3 came out, so now I’m working through each step, but this time aiming to release code and document the steps by blogging. I’m also going much deeper on exploring the potential of DuckDB to help in each step. I am pretty sure that if DuckDB continues to build out great spatial support it’ll be by far the best option for all the steps — at least for my particular set up of processing data mostly locally. I just released my first open source python project, which only really does the first step of removing multis and turning into fgb or parquet. But I got fascinated by the performance characteristics of these transforms and formats, so I added a few different paths and made a ‘benchmark’ command that compares the times.
Next up I’ll blog about that experience, and then I hope to compare at least PostGIS and DuckDB for the big spatial join step. I’m interested in having BigQuery (or other geospatial cloud data warehouses) and Apache Sedona in the mix, though I’m not sure I’m set up to use them. So I’ll likely try to get open source code to compare and then hope that others can contribute other processes. And then hopefully do all the things I was planning to do with v3. I also liked the idea of trying to combine Google and Microsoft buildings into a single dataset as done in this blog post from VIDA Engineering. It’d be cool if you could see which buildings each uniquely got, and also conflate the ones that were the same and compare their confidence, and perhaps even their exact boundaries.
